Have you ever tried running a Java application on AWS Lambda? Well, even the simplest Java application takes significant time to start up at first. And it’s not some Java specific limitation, but other runtimes like .NET suffers from the same. The reason behind is simple. AWS has to prepare a runtime environment for your application when it executes the first time. This is called cold-start. When the environment is already prepared, the JVM is ready to go and only your application code needs to be invoked. This is called warm-start. Although after some time, a warm Lambda environment will be killed by AWS in case there’s no invocation, and the same cold-start will occur.
There are a number of different ways how to mitigate cold startup times. You can use Provisioned Concurrency to tell AWS how many Lambda environments you want to be ready at all times. You can try to tackle it by having a CloudWatch trigger that periodically calls your Lambda, and thus keeping it warm.
I’d like to take you to a merely different journey to fight cold startup with GraalVM and native images.
The idea
I was always wondering what GraalVM is capable of. I’ve read several articles how great it is, and how unbeliavable it speeds up Java applications. I’ve tried it myself with a simple Spring Boot app, and well. The startup time was really impressive. But I didn’t really get why startup time is so crucial for a normal Spring Boot application. Then it hit me, how great it would be if GraalVM is used in the serverless world with AWS Lambda.
In normal circumstances, with a simple Java application (and I mean simple, like a Hello World example), Lambda is slow in case of cold-start.
When you spice it up with a little DynamoDB writing, the cold-start response time becomes unacceptable.
The average cold startup time for the simple Java app is 376ms while if a single DynamoDB entry is written upon request, it averages at 11 940ms. Yeah, that’s not a typo, almost 12 seconds. Although let me emphasize the fact that the 2 tests were executed on different memory settings because the DynamoDB example didn’t even start with a 128MB lambda function in a reasonable time.
When I’m looking at the warm startup times, here’s how it looks.
Much better. On average the DynamoDB example takes 175ms to execute which is a pretty big difference compared to the cold response time.
Okay, let’s jump into native images and GraalVM. The concept behind GraalVM’s native image is to compile Java code ahead-of-time (AoT) into a standalone executable without the need to run an actual JVM. From a practical standpoint, it just means whatever your application code needs, it will be packaged into a single binary, e.g. JDK classes, garbage collector, application classes, everything. The resulting executable is bound to the operating system it’s been compiled to, but it’s much faster and memory efficient than it’s brother running on the JVM.
So what if the same technology is used in a lambda function? Well, in 2018, AWS announced their support for a feature called Custom runtimes.
Custom Lambda runtimes
What is a custom runtime in the first place? There are well-defined APIs by AWS in any Lambda environment, and how any of the functions are interacting with the AWS environment. The Runtime API docs defines these interactions. It’s a set of HTTP APIs to call, and that’s it. If there’s any language you want to use in your Lambda, you can very well just write your own Runtime API implementation and package it in a way AWS can invoke it, and that’s it.
In addition to the Runtime API, AWS looks for a file called bootstrap. This is the entrypoint for any custom runtime function. This is what AWS will call upon invocation.
A custom runtime has to be provided to Lambda in the form of a ZIP archive. In the root of the ZIP, there has to be the bootstrap file, and that’s it. Simple, right?
Since the plan is to create a native image from the Java application, and run even the Runtime API implementation as part of the native image, I needed a Java-based implementation of the runtime. However, to my surprise I wasn’t really able to find a suitable solution, so I decided to write my own. I won’t go into the details right now, but here’s the code.
So in theory, there are going to be 2 files within the ZIP archive, a bootstrap file and the native image. And the boostrap file is just going to be a simple bash script invoking the native executable, like this:
#!/bin/sh set -euo pipefail ./function -Xmx256m -Djava.library.path=$(pwd)
Now, the next thing, the application code. Let’s try with a simple Lambda function that returns whatever has been passed as a parameter.
I’m using Gradle here with Shadow to package into a fat JAR.
plugins {
id 'com.github.johnrengelman.shadow' version '6.1.0'
id 'java'
}
group = 'io.redskap'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '11'
repositories {
mavenCentral()
}
dependencies {
implementation 'io.redskap:aws-lambda-java-runtime:0.0.1'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.3.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.3.1'
}
test {
useJUnitPlatform()
}
shadowJar {
manifest {
attributes 'Main-Class': 'io.redskap.lambda.runtime.sample.NativeApp'
}
}
We’ll need the usual AWS SDK handler interface implementation as the following:
public class IdentityRequestHandler implements RequestHandler<String, String> {
@Override
public String handleRequest(String input, Context context) {
return input;
}
}
Okay, this is good, but the runtime has to be spun up as the entrypoint of the native image, so let’s create an entrypoint.
public class NativeApp {
public static void main(String[] args) {
new LambdaRuntime(asList(
new RequestHandlerRegistration<>(new IdentityRequestHandler(), String.class, String.class)
)).run();
}
}
The LambdaRuntime class comes from the runtime implementation I’ve created, and the handler implementation has to be registered, that’s it.
Putting the puzzle together
Well, the foundation is ready for the simple application. The next thing is building. Since the end result is going to be a native executable, obviously we can’t compile it on our local machine – unless you’re running the same OS as Amazon is running on their Lambda environments. 🙂
I’ll use Docker for building and copying the resulting native package out of the image. Here’s my Dockerfile.
FROM gradle:6.8.3-jdk11 as builder
COPY --chown=gradle:gradle . /home/application
WORKDIR /home/application
RUN gradle clean shadowJar --no-daemon
FROM amazon/aws-lambda-provided:al2.2021.03.22.18 as graalvm
ENV LANG=en_US.UTF-8
RUN yum install -y gcc gcc-c++ libc6-dev zlib1g-dev curl bash zlib zlib-devel zip tar gzip
ENV GRAAL_VERSION 21.0.0.2
ENV JDK_VERSION java11
ENV GRAAL_FILENAME graalvm-ce-${JDK_VERSION}-linux-amd64-${GRAAL_VERSION}.tar.gz
RUN curl -4 -L https://github.com/graalvm/graalvm-ce-builds/releases/download/vm-${GRAAL_VERSION}/${GRAAL_FILENAME} -o /tmp/${GRAAL_FILENAME}
RUN tar -zxf /tmp/${GRAAL_FILENAME} -C /tmp \
&& mv /tmp/graalvm-ce-${JDK_VERSION}-${GRAAL_VERSION} /usr/lib/graalvm
RUN rm -rf /tmp/*
CMD ["/usr/lib/graalvm/bin/native-image"]
FROM graalvm
COPY --from=builder /home/application/ /home/application/
WORKDIR /home/application
ENV BUILT_JAR_NAME=aws-lambda-java-native-0.0.1-SNAPSHOT-all
RUN /usr/lib/graalvm/bin/gu install native-image
RUN /usr/lib/graalvm/bin/native-image --verbose -jar build/libs/${BUILT_JAR_NAME}.jar
RUN mv ${BUILT_JAR_NAME} function
RUN chmod 777 function
RUN zip -j function.zip bootstrap function
ENTRYPOINT ["bash"]
I won’t go into every single detail, here’s the high-level flow:
- Build the application’s fat JAR with Gradle and Shadow
- Spin up an AWS Lambda container, install the necessary Linux tools and download GraalVM
- Copy the fat JAR into the same container
- Execute GraalVM’s native-image builder
- Change the permissions of the built executable
- Make the ZIP archive from the executable and the
boostrapfile
After building the image with the following command:
$ docker build . -t aws-lambda-java-native
Let’s start up a container from the image:
$ docker run --rm -it aws-lambda-java-native
This will keep the container running until we can copy out the archive.
In another terminal window, let’s execute the following commands:
$ docker ps $ docker cp <container id>:/home/application/function.zip build/function.zip
The copied archive will contain the 2 necessary files. The next thing is to head towards the AWS Console, and create a Lambda function with Custom runtime on Amazon Linux 2.
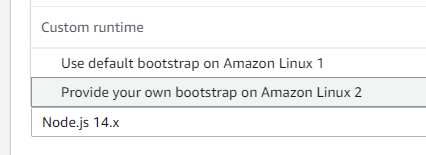
Upload the ZIP archive on the Code tab, and set the handler, in my case io.redskap.lambda.runtime.sample.IdentityRequestHandler::handleRequest. Although the ::handleRequest is not necessary, I’ve just put it there for consistency reasons with the standard Java lambdas.
Going to the Test tab and running the hello-world template will have the following result.
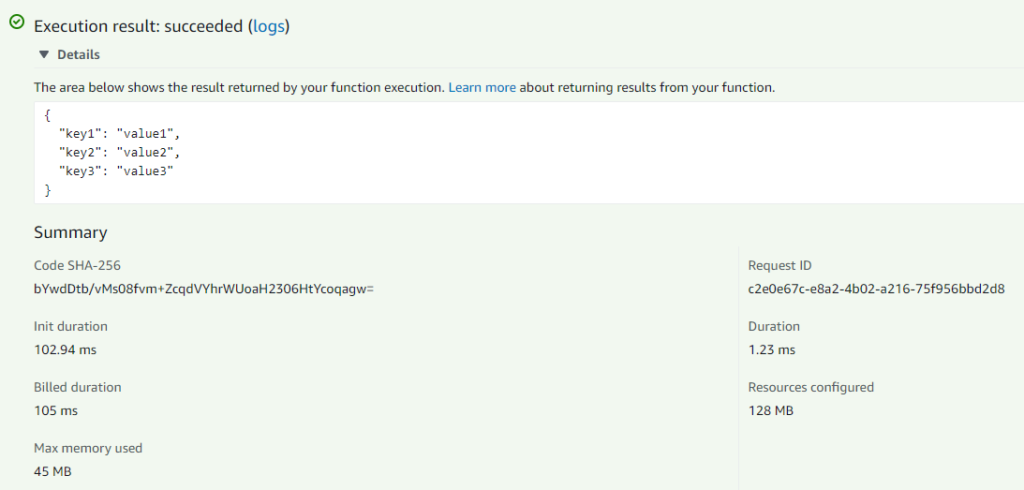
Pretty neat, right? If I’m going back to the original JVM Java example, on cold-start average it took 376ms to execute. In the case of the native image, it was 105ms. Here are some numbers for the native image separately:
The native image is ~2x faster even for this simple example.
You can find the full code here on GitHub. Also, for the ease of building the native executable, the Docker magic is implemented in Gradle in the example, and the ./gradlew clean buildNative command can be used to generate the function.zip.
Complicating it with DynamoDB
I always like examples that are more realistic, so I decided to build a function that’s writing a new entry into DynamoDB upon invocation.
Here’s the request handler:
public class TestRequestHandler implements RequestHandler<TestRequest, String> {
@Override
public String handleRequest(TestRequest input, Context context) {
AmazonDynamoDB dynamo = AmazonDynamoDBClientBuilder.standard().withRegion(Regions.EU_CENTRAL_1).build();
PutItemRequest putItemRequest = new PutItemRequest();
putItemRequest.setTableName("test-db");
HashMap<String, AttributeValue> items = new HashMap<>();
items.put("id", new AttributeValue(UUID.randomUUID().toString()));
items.put("name", new AttributeValue(input.getName()));
putItemRequest.setItem(items);
dynamo.putItem(putItemRequest);
return input.getName();
}
}
Nothing special. The request shall be a JSON with a name attribute. That name attribute value will be taken and inserted into a test-db Dynamo table with a randomly generated UUID.
Pretty simple right. I’ll use the same implementation for generating a native image. The complication for GraalVM comes from code using reflection. When generating the native image, and compiling the classes into the executable is based on static code analysis, meaning that code using any type of reflection calls will be invisible for GraalVM.
And oh boy, you can’t even imagine how many libraries are using reflection under the hood. I was hoping that the AWS Java SDK wouldn’t heavily rely on reflection calls, but I guess I was wrong.
For these classes, you have to tell GraalVM exactly the fully qualified names so it can compile them into the image. This can be done multiple ways, one is to provide a reflect-config.json file within the JAR. Here’s a piece of the actual file:
[
{
"name": "io.redskap.lambda.runtime.sample.TestRequest",
"allDeclaredFields": true,
"allDeclaredConstructors": true,
"allDeclaredMethods": true,
"allDeclaredClasses": true
},
{
"name": "org.apache.commons.logging.LogFactory",
"allDeclaredFields": true,
"allDeclaredConstructors": true,
"allDeclaredMethods": true,
"allDeclaredClasses": true
},
...
]
As you can see, the first class is the actual TestRequest class I’ve used in the handler, so the custom runtime is able to instantiate the class when deserializing the JSON request, and well, that’s reflection already.
The full file can be found here.
Next up, creating runtime proxies. Again something frameworks heavily rely on. The underlying HTTP client library for the AWS SDK needs this as well. GraalVM needs to be told exactly which interfaces the proxy will implement. This can be set by the proxy-config.json:
[ ["org.apache.http.conn.HttpClientConnectionManager", "org.apache.http.pool.ConnPoolControl", "com.amazonaws.http.conn.Wrapped"], ["org.apache.http.conn.ConnectionRequest", "com.amazonaws.http.conn.Wrapped"] ]
And you specifically need to tell GraalVM which resource files to include, and fortunately the AWS SDK depends on a few of them, resource-config.json:
{
"resources": {
"includes": [
{
"pattern": "META-INF/services/.*"
},
{
"pattern": "com/amazonaws/partitions/endpoints.json"
},
{
"pattern": "com/amazonaws/internal/config/awssdk_config_default.json"
},
{
"pattern": "com/amazonaws/sdk/versionInfo.properties"
}
]
}
}
And the last thing. We gotta tell the native image builder to enable the HTTPS protocol communication for the executable (because the SDK talks to AWS via secured channels) and to allow classes to be compiled without their static dependencies being present.
Args = --allow-incomplete-classpath --enable-url-protocols=https
The builder will pick up all these files under META-INF/native-image and generate the image accordingly.
The next thing is the same except you need to create the DynamoDB table and configure the necessary IAM role for access. Upload the ZIP archive to AWS, configure the handler and invoke it with the following request:
{
"name": "test"
}
Results
Okay, the most exciting thing, how did the native image perform during cold starts?
Just for reference, I’ve put there the vanilla JVM implementation response times. On average that performed with ~12 sec response time, while even the 128MB native image has finished its execution in ~2.7 seconds. As soon as the memory is increased to 512MB on the native image, it goes down to 785ms. With further increasing the memory to 1024MB for the native image, it performs even better.
Now the warm-starts, let’s see.
Well. The average response time even with a 128MB native image goes lower than the JVM-based implementation with 512MB. That’s impressive. And with further increasing the native image function memory to 512MB, on average it goes down to 38ms which is negligible.
I’ve also done the same measurement with a NodeJS app to see how it performs compared to the Java version.
As you can see, the 128MB NodeJS version produces similar results like the 512MB native image version.
Regarding warm startup times, here are the results.
The average response time is pretty low, even with 128MB, it’s only ~150ms but at 512MB, it goes down to 38ms.
Conclusion
I think it’s needless to say. Running native images in the Lambda environment is impressive. However it definitely brings in some complexity if you deal with libraries that are using reflection. The good thing is, GraalVM provides a special agent that can be attached to your application to record what classes/resources/etc are being used during runtime and generate an initial version of the configuration files.
Also, for any type of Lambda function, it’s critical to be conscious about the size of your dependencies and keep them to the minimum.
I think there is great potential on using native images and it’s worth experimenting with.
As always, the full samples and the runtime can be found on GitHub. If you have questions/ideas, leave them in the comments below or find me on Twitter.
We are working on a similar thing (although my runtime doesn’t run GraalVM to create a native image but instead uses jlink). I have a question about trying to get AWS Codeguru Profiler running on a custom java runtime – you may be interested: https://github.com/aws-samples/aws-codeguru-profiler-demo-application/issues/20
So far I haven’t found anyone using codeguru profiler yet – but I think it would be a very useful tool.
Impressive work sir.
Got the first one up and running tks to all your hard work. Now to unpack into the rest of our environment and see how we can automate a lot of these.
Well done! This helped me get started with Graalvm